
When working with Elasticsearch, it's common to encounter situations where data needs to be kept in sync between the Elasticsearch (ES) index and another primary database, such as Postgres, MySQL, or MongoDB. This is often the case when Elasticsearch is not the best choice as a primary database, but its fast and cost-effective full-text search capabilities are still needed. To ensure that users are presented with the most recent and accurate information when performing a search, it is crucial to keep data in sync between the primary database and Elasticsearch.
Therefore, to address this issue, below we will discuss different methods for maintaining continuous synchronization between your primary database and Elasticsearch (ES), to ensure that your application is always using the most up-to-date data.
Synchronizing with ES in the same database transaction
One simple and easy-to-implement technique for keeping your Elasticsearch data up-to-date with your primary database is to store the relevant data in both places within the same transaction. In this technique, whenever you store the data (or more precisely the data that you want to be searchable) in your primary database, then you also store it in Elasticsearch in the same transaction.
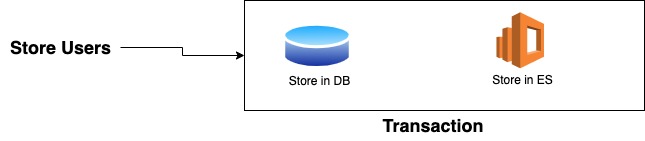
For example, in the above image, when a "Store User" action is triggered, the data is first stored in the primary database and then in the Elasticsearch index. But, It is important to note that this should be done within the same transaction to ensure consistency and the ability to roll back in case of errors. In the code, it would be something like this:

This technique is beginner-friendly, but it is very important to understand the concept of transactions. For more information on transactions, you can refer to the following resource: https://fauna.com/blog/database-transaction
Using Message Queue or Pub/Sub Model
Message Queues and Pub/Sub are simple yet powerful techniques for facilitating communication and data transfer between multiple software systems. They enable asynchronous communication by allowing messages to be sent and received between two independent applications. These models can be effectively utilized to maintain continuous synchronization between a primary database and Elasticsearch. By enabling communication between the two systems, data can be easily and consistently updated.
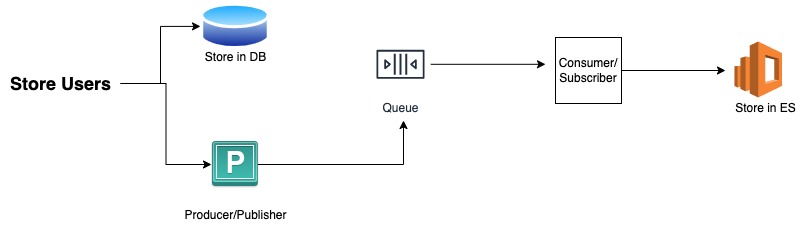
As an example, in the above image, when a "Store Users" event is triggered, the data is first passed to the primary database for storage and subsequently passed to a producer which sends it to a message queue. Later, a consumer then retrieves the message from the queue and stores it in Elasticsearch.
This technique is extremely efficient as it offloads the storage task to the consumer server, rather than the main server, resulting in faster synchronization. It can be particularly beneficial when dealing with large payloads, as it reduces the storage time on the main server. However, it is important to note that this method also requires maintaining a separate message queue or pub/sub server, which can be costly.
Running a separate server to continuously check for changes in the DB
This is another technique where you will create a different server that periodically queries your primary database and check if there have been new entries in it. This technique can be useful when you already have a large amount of data in the primary database and wish to implement Elasticsearch later on.

For instance, in the image above, a server is placed in between the primary database and Elasticsearch, which continuously monitors for changes in the primary database and passes any new data to Elasticsearch for storage. However, it is very important to remember that this method can be highly resource-intensive and costly since it uses a separate server and periodically queries the primary database.
Using a third-party application
If you prefer not to use the previously discussed techniques, there are several third-party applications readily available that can help in synchronizing data between the primary database and Elasticsearch.
One of them is Debezium. As mentioned on their own website: "Debezium is an open-source distributed platform for change data capture. Start it up, point it at your databases, and your apps can start responding to all of the inserts, updates, and deletes that other apps commit to your databases. Debezium is durable and fast, so your apps can respond quickly and never miss an event, even when things go wrong."
This means that once Debezium responds with any update in the database, you can immediately trigger an event to insert or update the data into your ElasticSearch cluster.
Another application is ABC CLI, which is created by Reactive Search, and has very limited functionality. Currently, it only supports real-time data synchronization with MongoDB and Postgres and is only compatible with the Elasticsearch service hosted by Reactive Search.
The third alternative is using the Logstash which is created by the Elasticsearch team itself and JDBC. Synchronization using Logstash only works with RDBMS like MySQL, and Postgres and can be somewhat complex for beginners. For further information on this technique, you can refer to the article How to keep Elasticsearch synchronized with a relational database using Logstash and JDBC
Conclusion
In this article, we have discussed various techniques for maintaining continuous synchronization between a primary database and Elasticsearch. These techniques range from simple database transaction-based synchronization to more advanced methods such as utilizing message queues, creating a separate server for periodic checking, and utilizing specialized third-party applications. We also discussed methods that can be costly to operate and maintain. It is crucial to take into consideration the specific requirements and resources of your project when selecting a synchronization method. Third-party applications like Debezium and ABC CLI can be a valuable solution, but it's important to be aware of their limitations. Logstash and JDBC are suitable options for those familiar with them, but they are more complex than other alternatives. Whether it's an RDBMS like MySQL, or Postgres, or a NoSQL solution like MongoDB, it is important to keep in mind the type of primary database you are using and build a reliable synchronization solution that generates value for your software product. Ultimately, it's essential to evaluate the various options and choose the method that best suits your specific use case.
I hope this article has been helpful for both beginners and experienced developers who are learning Elasticsearch or seeking to integrate data between Elasticsearch and other databases. If you found this information useful, please consider sharing it with friends or colleagues who may also benefit from it. If you have any questions or would like to discuss the topic further, you can reach out to me on Twitter at https://twitter.com/aabiscodes or LinkedIn at https://www.linkedin.com/in/aabis7/.
Thank you for taking the time to read this article.